Blog 0.4: Spark Data Types and Structured API Execution
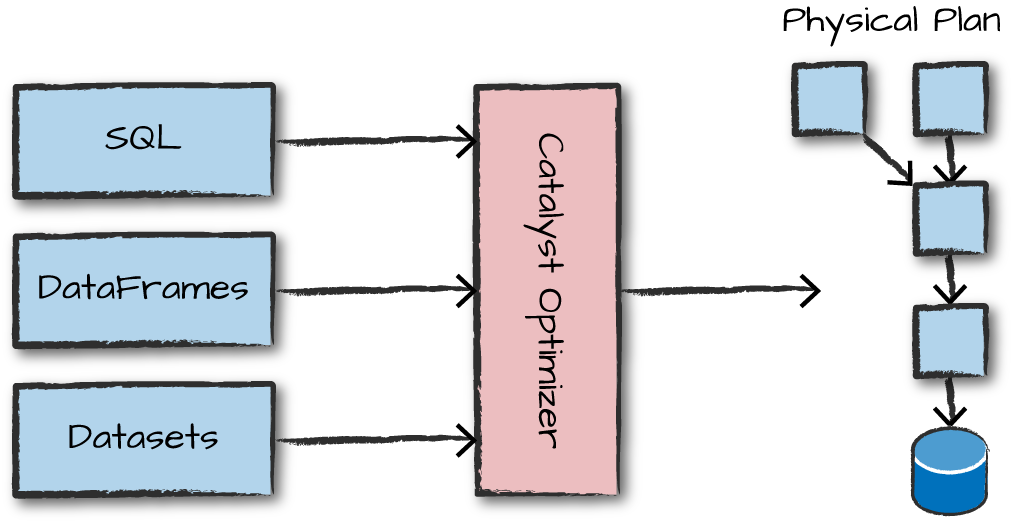
Spark Types and Structured API Execution
Spark has a large number of internal type representations. Spark uses an engine called Catalyst that maintains its own type information through the planing and processing of work. This allows to open up a wide vareity of execution optimizations that make siginificant differences.
We can use different language APIs that Spark maintains (Scala, Java, Python, SQL, and R).
Columns
Columns represent a simple type like an integer or string, a complex type like an array or map, or a null value. Spark tracks all of this type information which can be used for transforming columns.
Rows
A row is nothing more than a record of data. Each record in a DataFrame must be of type ROW. We can create rows mannually from SQL, Resilent Distributed Datasets (RDDs), data sources, etc.
Example to show the rows after building a Spark Session.
from pyspark.sql import SparkSession
spark= SparkSession\
.builder\
.appName('dataTypes')\
.getOrCreate()
Now, after creating a spark session we can generate Rows.
my_row= spark.range(10)
**Output: **
my_row.collect()
[Row(id=0),
Row(id=1),
Row(id=2),
Row(id=3),
Row(id=4),
Row(id=5),
Row(id=6),
Row(id=7),
Row(id=8),
Row(id=9)]
Different Data Types from Spark’s Langauge
Each data types have API calls to access or create a data type during execution during handling the dataframes and datasets. Mostly we will always manipulate the data and transform.
- ByteType= int or long. Note: numbers will be converted to 1-byte signed integer numbers at runtime. (129 to 127)
- StringType= String
- BinaryType= bytearray
- BooleanType= bool
- TimestampType= datetime.datetime
- MapType= dict
- StructField= The value type in Python of the data type of this field (for example, Int for StructField with the data type IntegerType)
Overview of Structured API Execution
I will demonstrate the code execution across cluster. This can help understand and debug the process of writing and executing code on clusters. By implementing followingsteps, we can execute single structured API query.
- Writing DataFrame/Dataset/SQL code
- If valid code, Spark converts this to a Logical Plan
- Spark Transforms this logical Plan to a Physical Plan, checking for optimizations along the way
- Spark then executes Physical Plan (RDD manipulations) on the cluster