Blog 0.0: Apache Spark Setup
Setting up Apache Spark on Windows
![]()
Apache Spark
Apache Spark is a data processing framework that is used for processing very large data sets, and can also distribute data processing tasks across multiple computers, either on its own or in tandem with other distributed computing tools.
Apache Spark Architecture
At a fundamental level, an Apache Spark application consists of two main components: driver whcih converts user’s code into multiple tasks that can be distributed across worker nodes, and executors which run on those nodes and execute the tasks assigned to them. Some of the cluster manager (Standalone, Hadoop YARN, Kubernetes) are necessary to mediate between two.
Local Mode
Spark can run in a standalone cluster mode that simply requires the Apache Spark framework and JVM on each machine your cluster.
Spark, in addition to its cluster mode also has Local mode. The driver and executors are simply processes, which live on the same machine or different machines.
In Local mode, the driver and executor runs as Threads on your individual computer instead of a cluster.
Setting up Environment Variable
Since the HDFS is not supported on windows, we need to install TWO files and place in a /bin directory of Hadoop where it has been originally downloaded.
hadoop.dll
winutils.exe
The above two files can be downloaded from the link below:
Download Apche Spark Tar file
The tar file spark-3.0.1-bin-hadoop3.2 can be download from the website below.
After downloading the file, unzip the file to a desired path on the drive.
Setting up PATH and directory
- For Window, open up a application Edit the System Environment Variables
- Select Advanced option and select Environment Variables
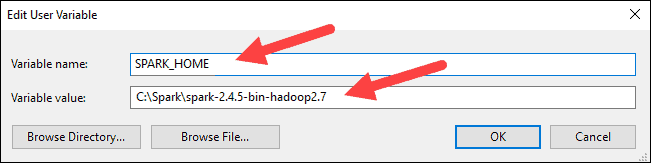
In the next step, System Variables section New and place the variable Names and Variable Value as follows:
Variable Name: SPARK_HOME
Variable Value: 'C:\Users\spark-3.0.1-bin-hadoop3.2'
In the next step, we should add path to /bin directory on the existing PATH on System variable section.
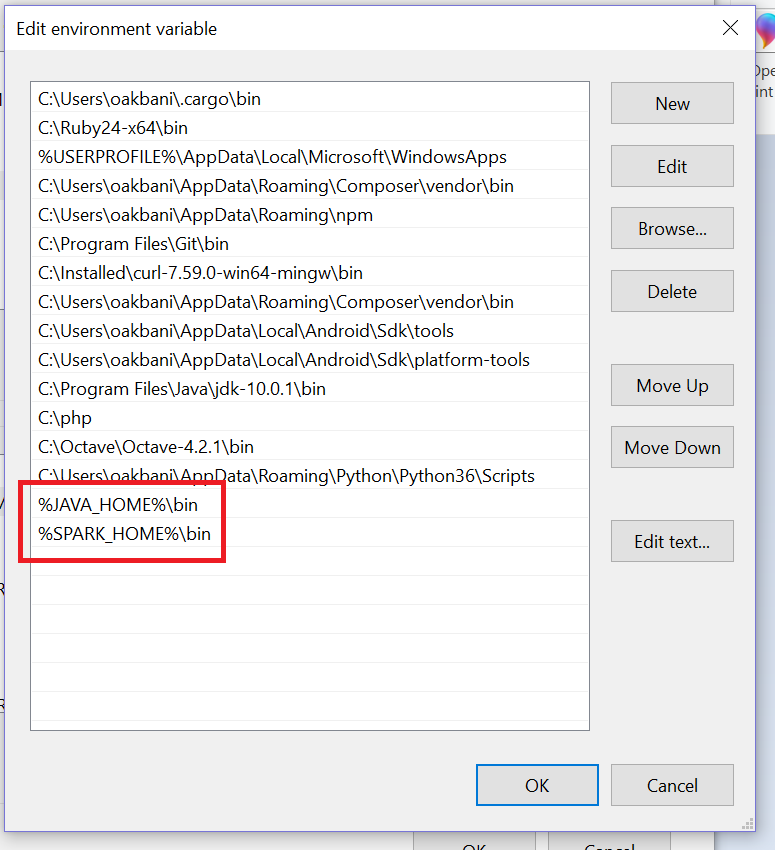
HADOOP HOME and JAVA HOME
We can follow similar steps for setting environment variable to HADOOP HOME and JAVA HOME as well.